




Nous testons les stratégies de ChataGPT – l’IA peut-elle vous aider à gagner de l’argent en bourse ?
ChatGPT génère des graphiques, écrit des logiciels et des articles ou analyse des données. Et il fait tout cela, du moins à première vue, bien. C’est pourquoi l’idée d’élaborer des stratégies de trading avec son aide a rapidement germé. Car si l’IA sait tout, peut-être connaît-elle aussi le secret pour gagner de l’argent sur le marché ? Malheureusement, dans la pratique, la question n’est pas aussi simple qu’il n’y paraît.
ChatGPT va-t-il écrire le système de trading pour nous ?
Pour mettre en pratique la capacité de ChatGPT à construire des stratégies (une capacité qui est aujourd’hui promue par les créateurs de YouTube et les vendeurs de cours), j’ai demandé au modèle de me donner des idées de systèmes de trading pour trois groupes : débutant, intermédiaire et avancé.
Le modèle propose trois solutions :
- Pour les débutants : Stratégie SMA Crossover (achat/vente après croisement de moyennes mobiles simples).
- Intermédiaire : RSI + Price Action (jouant les niveaux de surachat et de survente).
- Advanced : Momentum + Volatility Regime Filter (ATR) – acheter après des hausses excluant les périodes de forte volatilité.
En pratique, chacune des idées ci-dessus est destinée aux débutants ou, au mieux, aux traders intermédiaires. Bien que la dernière stratégie tente de filtrer les périodes de forte volatilité à l’aide de l’ATR, il s’agit d’un outil que les traders novices connaissent bien. En revanche, le modèle propose l’utilisation du Momentum, qui est parfois mis en œuvre dans de véritables systèmes de trading.
Néanmoins, il n’y a pas d’idées statistiquement avancées ou d’idées ayant une justification économique plus profonde. En clair, il s’agit de la bonne vieille analyse technique.
Toutefois, l’adjectif « bon » doit être pris ici entre guillemets, car ces types de méthodes sont connus dans la communauté pour leur inefficacité. Les intersections de moyennes mobiles sont le plus souvent un outil qui fonctionne assez bien dans les tendances directionnelles et qui restitue tous les gains dans les tendances latérales. L’inverse est vrai avec le RSI – il fonctionne dans les tendances latérales et devient une machine à perdre de l’argent lorsque le marché s’équilibre.
Non seulement l’hypothèse de l’efficience des marchés prouve que battre les indices est une tâche difficile, voire impossible, mais le robot ne nous a rien apporté de nouveau. Pour tirer des idées un peu plus logiques, vous devez savoir exactement ce que vous recherchez.
Stratégie pour les débutants : croisement des moyennes mobiles
Mais passons aux résultats. Après avoir reçu le code de toutes les stratégies, j’ai demandé au modèle de comparer les résultats du backtesting avec le Buy&Hold classique sur l’indice S&P500. Le premier système – basé sur les moyennes mobiles – a généré une perte de 28,47% depuis le 2010-01-01, comme prévu. Dans le même temps, la détention de l’indice S&P500 (ticker ^GSPC) dans le portefeuille a généré un gain de 449,87%.
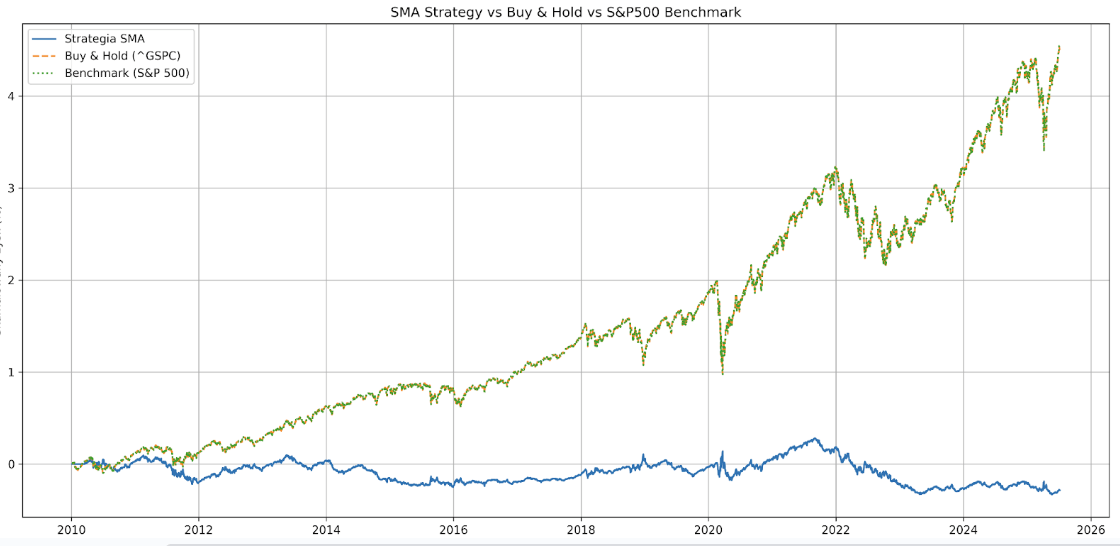
Par défaut, la stratégie utilise des moyennes mobiles avec des périodes de 20 et 50 :
Nous pouvons étendre ces périodes à 20 et 200, 21 et 200 et 50 et 200 pour réduire la fréquence des transactions et comparer les résultats de toutes les variantes sur un même graphique.
REMARQUE !
L’essai de différentes variantes de moyennes mobiles vise à trouver les paramètres les plus efficaces. Dans des conditions réelles, cela peut conduire à un surajustement de la stratégie aux données de test sur lesquelles les paramètres spécifiques fonctionnent le mieux (ce que l’on appelle le surajustement) et à une mauvaise performance de la stratégie dans les transactions réelles. Pour éviter cela, les traders utilisent généralement l’optimisation Walk-Forward, qui consiste en une vérification étape par étape de la stratégie sur des données successives.
C’est là que commencent les pierres d’achoppement, car un utilisateur qui ne comprend pas le code généré par le LLM peut avoir des difficultés considérables à effectuer une telle tâche. Lors de l’expansion du code, le chat génère parfois des erreurs logiques, et lorsqu’on lui demande de les corriger en se basant sur le message exact de l’erreur en question, de nouvelles erreurs sont commises.
Si nous avons de la chance, il finira par trouver la bonne solution. Dans le cas contraire, il n’y en aura jamais.
Dans ce cas, l’erreur était simple et Chat l’a éliminée après plusieurs tentatives. Il a généré un nouveau code avec plusieurs stratégies différant par la longueur de leurs moyennes mobiles. En outre, il a été chargé de mettre en place des statistiques supplémentaires pour chacune d’entre elles : glissement maximal du capital, volatilité annuelle, ratio de Sharpe et de Sortino, nombre de transactions et durée moyenne de détention. Des coûts de transaction de 0,1 % ont également été simulés. Le logiciel a très bien géré tous ces aspects.
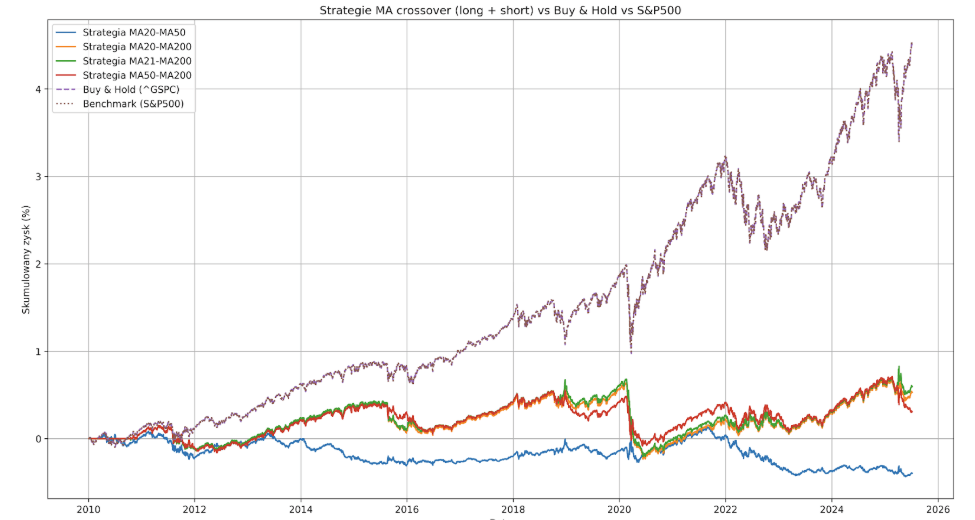
Les résultats sont déjà nettement meilleurs. La stratégie de base MA20-MA50 continue de générer une perte, cette fois de 39,61 %, en raison de la fréquence élevée des transactions (169) et des coûts associés. Les variantes MA20-MA200 et MA21-MA200 ont été les plus performantes, générant un gain de 52,99 et 59,48 % (avec seulement 33 transactions). Voilà pour les bonnes nouvelles – les bénéfices de presque toutes les stratégies ont été achetés avec un capital maximum de >50%. L’exception est MA50-MA200, qui a eu un Max Drawdown de -40,83% (mais n’a généré que 30,64% de profit).
Le clou du spectacle est bien sûr le S&P500 lui-même, qui a enregistré un rendement de 449,87 % au cours de la même période, avec une baisse maximale de -33,92 %. Comme prévu, aucune des stratégies basées sur les moyennes mobiles ne s’est avérée rentable.
La dernière chose que nous chercherons à faire est d’éliminer les positions courtes. Les moyennes mobiles ne serviront donc que de filtre pour nous permettre de clôturer une position longue lors d’un signal de vente, ce qui nous permettra peut-être d’attendre les périodes de baisse du S&P500 et de limiter les pertes en capital.
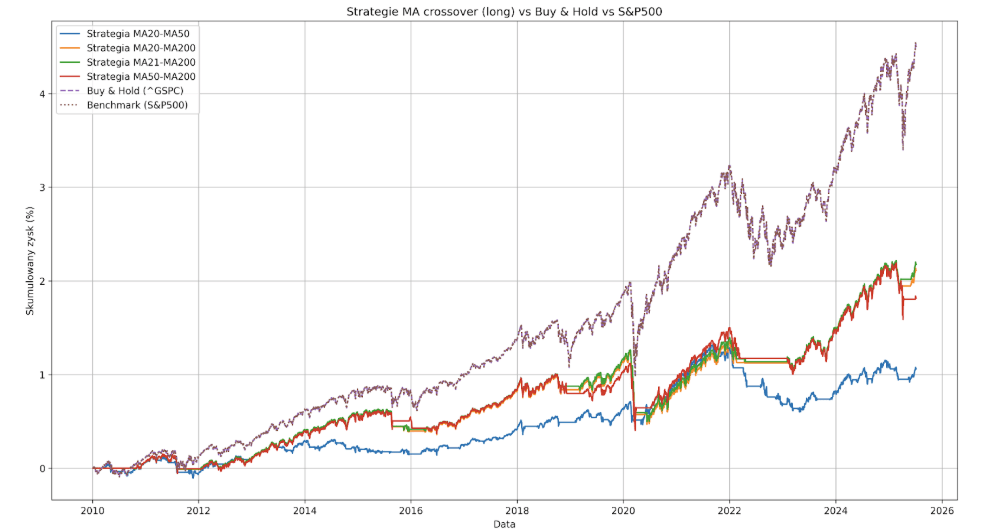
Comme vous pouvez le voir, c’est encore mieux. La stratégie MA20-MA50, qui a généré des départs jusqu’à présent, a réussi à réaliser un gain de 105,99% avec un Max Drawdown de -30,84%. La variante qui obtient le meilleur résultat est toujours MA21-MA200 (217,59%). Le glissement moyen du capital pour chaque stratégie se situe maintenant autour de -30%, ce qui est légèrement meilleur que le S&P500. En dehors de cela, cependant, peu de choses ont changé. Le système le plus performant ne génère toujours que moins de la moitié du rendement de l’indice (217,59 % contre 449,87 %), ce qui signifie que son utilisation n’a aucun sens.
Il ne faut pas non plus oublier que les stratégies sont toujours testées sur l’indice S&P500, qui prend de la valeur sur le long terme, et qu’il n’est donc pas surprenant de réaliser des bénéfices. Les intersections de moyennes sont toutefois très populaires auprès des traders qui jouent sur les paires de devises qui fluctuent et s’inscrivent moins souvent dans des tendances à long terme.
Nous passons donc à la paire EURUSD, nous activons les positions courtes et les stratégies basées sur les MA montrent ici leur vrai visage.
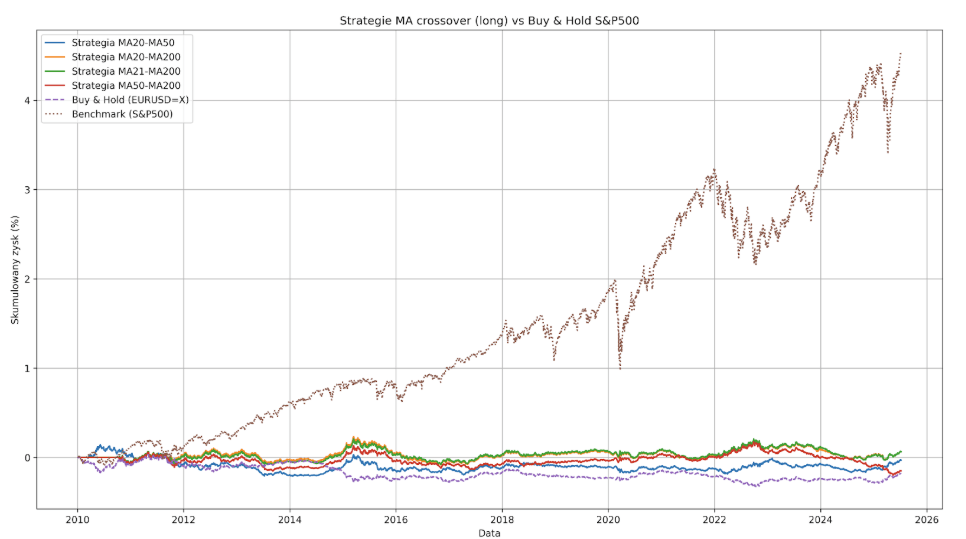
Le Max Drawdown du plus mauvais d’entre eux est supérieur à 35%, tandis que le gain généré par le meilleur d’entre eux n’est que de 6,34% et est très probablement totalement aléatoire.
Il faut dire que ChatGPT peut être un outil très utile pour les débutants, car avec un minimum de connaissances techniques, limitées à la capacité d’utiliser un Jupyter Notebook, il peut réellement prouver que les systèmes promus sur Internet et basés sur de simples indicateurs ne fonctionnent pas. Et s’ils fonctionnent, ils génèrent des résultats qui sont loin de battre les indices de référence. Il est alors facile de conclure qu’au lieu de s’amuser avec le trading, il serait plus sage d’acheter simplement le S&P500.
Le dernier test en date a lieu sur le marché du bitcoin.
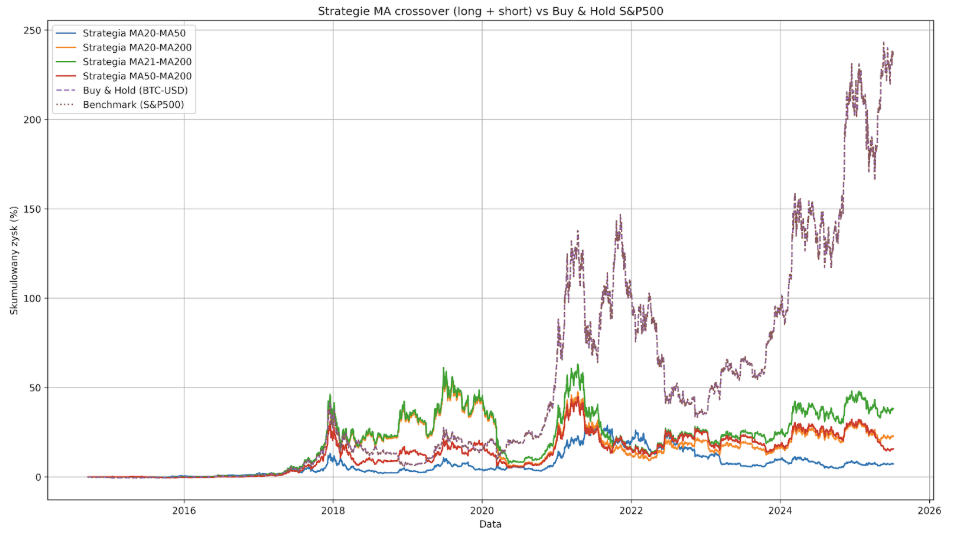
Peut-être parce que le BTC est un marché jeune et qu’il était jusqu’à récemment dominé par les traders particuliers, les stratégies de trading long/short basées sur les moyennes mobiles génèrent quelques profits ici. Cependant, le Max Drowdown pour chacune de ces stratégies est comparable à celui du Bitcoin lui-même et dépasse les 80 %, les profits étant plutôt maigres.
La stratégie Buy&Hold du bitcoin depuis septembre 2014 a généré un profit de 23 614 %, alors que la meilleure stratégie testée sur la même période n’a généré qu’un profit de 3805 %. C’est un résultat plus de six fois pire avec les mêmes feuillets de capital.
Comme pour le S&P500, il nous reste à cocher l’option Long Only, qui peut nous permettre d’améliorer la performance et de réduire le Max Drawdown.
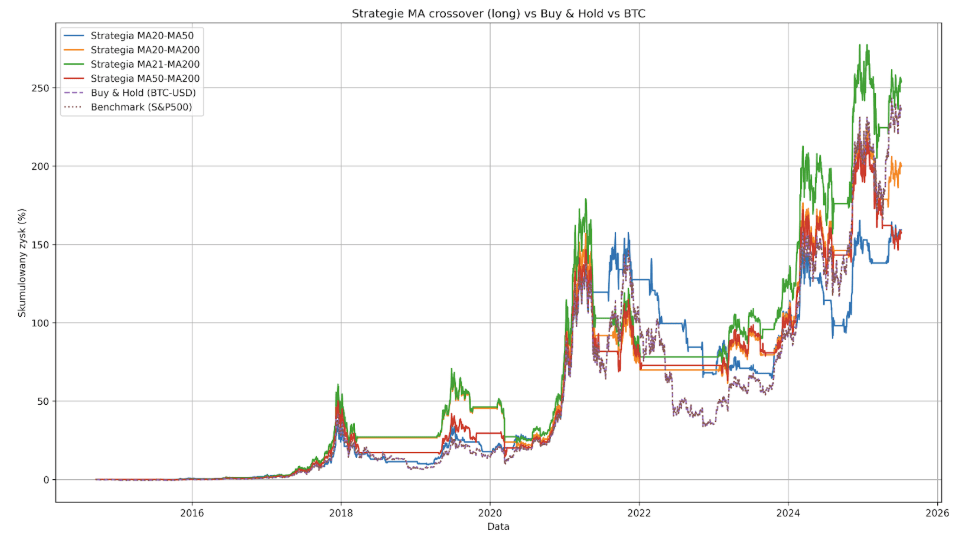
Dans ce cas, la stratégie MA21-MA200 a réussi à battre le score du Bitcoin (25416% contre 23646%) tout en réalisant un Max Drawdown plus faible (-66% contre -83,40%). Toutefois, le problème réside dans le nombre minimal de transactions (21), la manie spéculative du bitcoin au cours de la dernière décennie et son âge. Il est difficile de dire si la performance relativement bonne de stratégies aussi simples est due à leur valeur réelle ou plutôt à l’immaturité des crypto-monnaies et à la sensibilité aux conditions économiques observées depuis un certain temps et à la tendance à monter avec les indices américains.
Stratégie intermédiaire : niveaux RSI classiques
Deux systèmes doivent encore être testés : le système intermédiaire et le système avancé.
La première est basée sur l’indicateur RSI. Si la valeur du RSI est inférieure à 30, le marché est considéré comme survendu et nous ouvrons une position longue. S’il est supérieur à 70, nous considérons que le marché est suracheté et nous ouvrons une position courte.
La stratégie écrite à l’origine par ChatGPT ne maintient une position que pour un jour par défaut, j’ai donc demandé au modèle de l’étendre avec une gestion du risque de base. Le Take Profit a été fixé à l’ATR x2 et le Stop Loss à l’ATR x3.
En même temps, c’était probablement le cas le plus intéressant, car le robot a commis une erreur logique, ce qui a complètement faussé le résultat du backtesting. Avec un SL égal à ATR x 1,5 et un TP égal à ATR x3, soit un ratio RRR de 1:2, la stratégie battait la performance de l’indice S&P 500 à plate couture, générant plusieurs fois le profit. En revanche, avec des positions courtes exclues et un stop loss et un take profit égaux à ATR x 2… elle a fait faillite. Pourtant, du fait de l’absence d’effet de levier et de l’ouverture exclusive de positions longues sur le S&P500, qui est en hausse à long terme, il aurait dû gagner quelque chose.
Après avoir examiné le programme, il est apparu que ChatGPT, au lieu de compter le profit/la perte d’une position lorsqu’elle était fermée, ajoutait son retour à la série Returns après la création de chaque bougie, la traitant comme une transaction séparée. De cette manière, il importait peu qu’une position longue, sans stop loss, ait perdu x% au plus bas, mais qu’elle soit finalement gagnante. Chaque glissement de prix quotidien ajouté par le code s’ajoute aux pertes affichées.
Les lignes défectueuses ont été éliminées et la performance est redevenue prévisible. Depuis 2010, l’indice de référence a atteint 452% et notre stratégie long/short avec un RRR de 1:2 : -42,55%. Avec un départ en 1990, la perte était déjà de -66,64%.
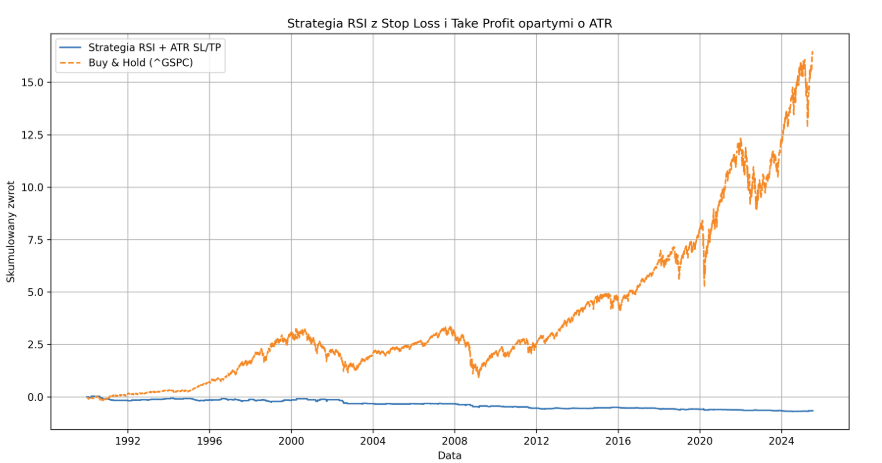
Les variances du long-only sont respectivement de -16,43 et -46,96%. Après avoir inversé le RRR à 2:1 (2j de perte pour 1j de gain), les résultats s’améliorent légèrement : 8,14% depuis 2010 et -28,64 depuis 1990 : 8,14% depuis 2010 et -28,64 depuis 1990. Il restait à tester une version qui gagne souvent des centimes et perd moins souvent des montants importants (avec un RRR de 12:1). Le rendement est ici de 9% depuis 1990 et de -11,66% depuis 2010 : -11.66%.
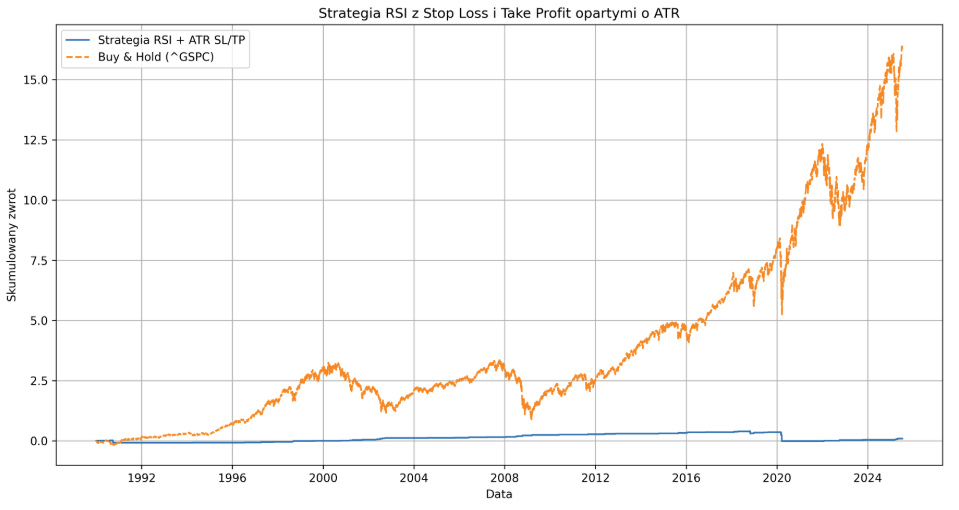
Cette stratégie a été un véritable désastre sur le marché du bitcoin. Avec long + short et un RRR de 1:2, elle a perdu 89% de son capital depuis 2010. Les modifications de SL et TP n’ont servi à rien et n’ont fait que réduire le drawdown. En raison des gains historiques de BTC, il a été possible de désactiver le short à RRR 2:1 : 436,19% et RRR 1:1 : 1024,37%.
Sur la paire EURUSD, en revanche, la performance a oscillé autour de -18%.
Une stratégie pour les « avancés » : le momentum et l’indicateur ATR
La stratégie avancée générée par ChatGPT s’est également révélée être une perte de temps. Le système utilise l’indicateur ATR pour filtrer la volatilité et, sur cette base, classe l’état du marché. Si la volatilité de l’instrument est statistiquement faible et que son prix a augmenté au cours des 10 derniers jours, la stratégie ouvre une position longue.
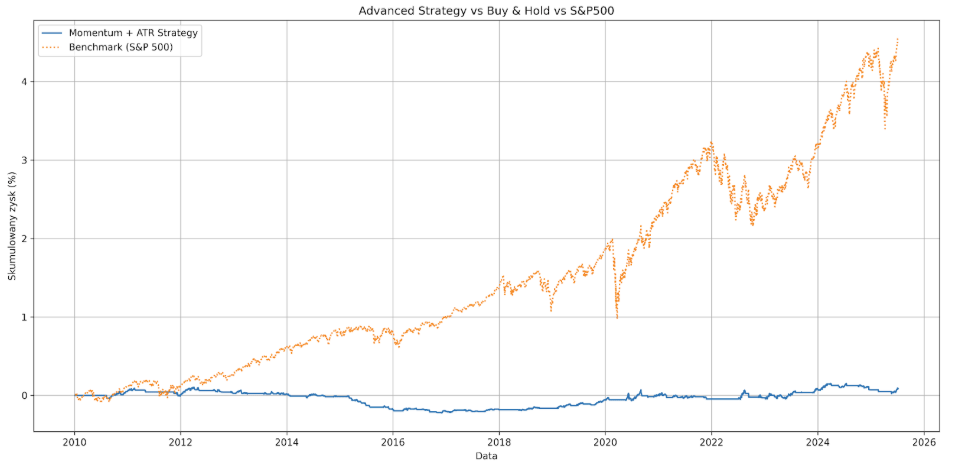
Cela a permis de limiter le Max Drawdown à 8,52%, mais comme vous pouvez le voir sur le graphique, le système a manqué une grande partie de la phase de hausse du S&P500, en restant sous la barre pendant près de 3 ans. Au final, le système a généré un rendement symbolique de 8,5 %, ce qui était probablement une coïncidence et le résultat d’un petit échantillon (315 transactions et 15 ans de vie du marché).
Vous pouvez d’ailleurs le vérifier en changeant la date de début de 2010 à 1990.
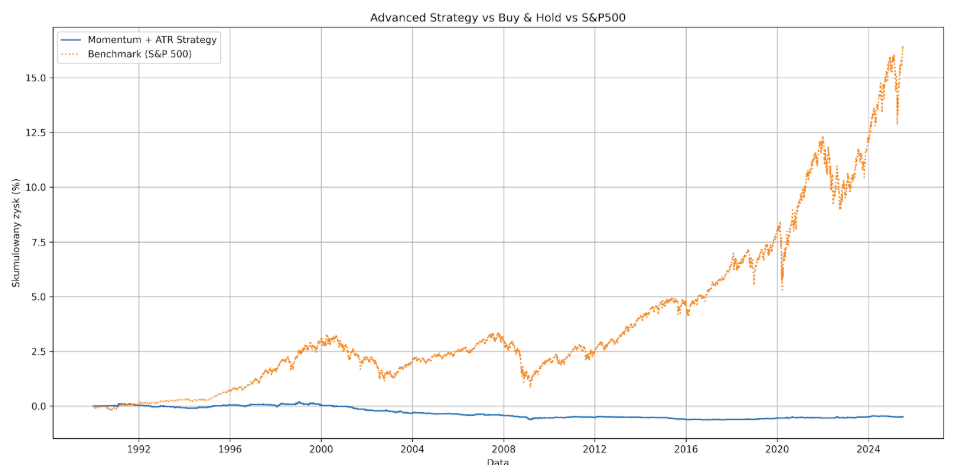
Aujourd’hui, au lieu d’un léger gain, nous constatons une perte de près de 48 %.
Stratégies ChataGPT vs. backtesting réel
Aucune des stratégies n’a généré de résultats satisfaisants, mais ce n’était pas le plus gros problème, mais le fait que ChatGPT n’a pas guidé l’utilisateur dans la bonne direction en proposant des backtestings plus sérieux. Il ne l’a pas averti du glissement des prix dans des conditions réelles, un surajustement qui peut faire en sorte que les bonnes performances d’une stratégie lors des tests se répercutent sur les opérations en direct. Il n’a pas proposé de ventilation des données (données d’entraînement et données de test) dans l’échantillon et hors de l’échantillon, d’optimisation, de validation Walk-Forward ou de méthode Monte Carlo pour générer différentes permutations de la courbe de capital générée par le système.
Il s’agit peut-être d’une coïncidence ou le problème pourrait être résolu par des commandes plus précises et plus détaillées. Le fait est qu’un trader qui s’attend à ce que le modèle génère une stratégie toute prête, qui ne comprend pas entièrement le code qu’il reçoit et qui n’a pas les connaissances nécessaires pour effectuer un backtesting correct, ne saura probablement pas quoi demander et quelles commandes donner au modèle. Cela signifie que ChatGPT est un peu comme un moteur de recherche Google sur les stéroïdes – un outil pour quelqu’un qui sait exactement ce qu’il cherche. Le modèle ne nous prendra pas par la main et ne construira pas un système monétisé pour nous.
L’intelligence artificielle « réelle » sur le marché boursier
En effet, les LLM dans le trading sont utilisés lors du traitement de l’actualité financière pour déterminer le sentiment des médias et bien plus encore. En ce qui concerne les algorithmes d’IA utilisés pour travailler avec des données financières, il s’agit souvent de modèles tels que les LSTM (Long-Short-Term-Memory), qui sont des réseaux neuronaux conçus pour traiter et prédire des séquences de données, grâce à leur capacité à « mémoriser » l’information sur une longue période de temps.
Plus important encore, les prix des instruments financiers dépendent d’un grand nombre de facteurs et contiennent beaucoup de bruit, de sorte que les algorithmes font rarement des prédictions. Le plus souvent, ils tentent de prédire les variables susceptibles d’affecter le prix. Ainsi, un trader sur les marchés d’actions peut utiliser l’IA, par exemple, pour prédire les performances de vente d’une entreprise particulière, et un trader sur les paires de devises pour prévoir la valeur des indicateurs économiques.
Les tentatives de formation de modèles sur des prix historiques, en particulier à la maison et avec l’aide de ChatGPT, aboutiront au mieux à la création d’une stratégie qui apprend les données de formation, mais qui cessera de donner de bons résultats en dehors de cet échantillon et dans les transactions en direct parce que les « modèles » qu’elle a reconnus s’avéreront être du bruit de marché.
ChatGPT doit donc être considéré comme un assistant qui accélère le travail, mais ne le fait pas à notre place. Ce n’est certainement pas une boîte magique qui produit des stratégies qui battent les résultats de référence, et la raison en est très simple – LLM ne pense pas, mais prétend penser, en utilisant des statistiques.
Comment fonctionne réellement le Chatbot ?
En termes simples, tous les LLM remplissent une condition : ils sont des modèles statistiques du contenu sur lequel ils ont été formés et prédisent le mot suivant dans la séquence. Ils génèrent quelque chose qui ressemble à la création d’une entité rationnelle, mais ce n’est le cas que parce que les textes sur lesquels ils sont enseignés ont été créés par l’homme.
En réalité, leur construction est plus compliquée et repose sur l’algèbre linéaire. En effet, le modèle ne prévoit pas de mots tels que nous les comprenons, mais ce que l’on appelle des tokens, ou groupes de caractères. En outre, ces jetons sont en fait des valeurs numériques (vecteurs) dans une matrice (appelée tenseur). De cette manière, le modèle effectue des opérations sur des vecteurs représentant différents morceaux de texte, en apprenant sur d’énormes ensembles de données à prédire des séquences de tokens dans différents contextes. Le transformateur est chargé de convertir les jetons en vecteurs dans la matrice (appelés « embeddings »).
Par exemple, dans l’exemple ci-dessous, nous voyons un fragment de tenseur représentant une phrase simple : « Le chat est couché sur le tapis ».
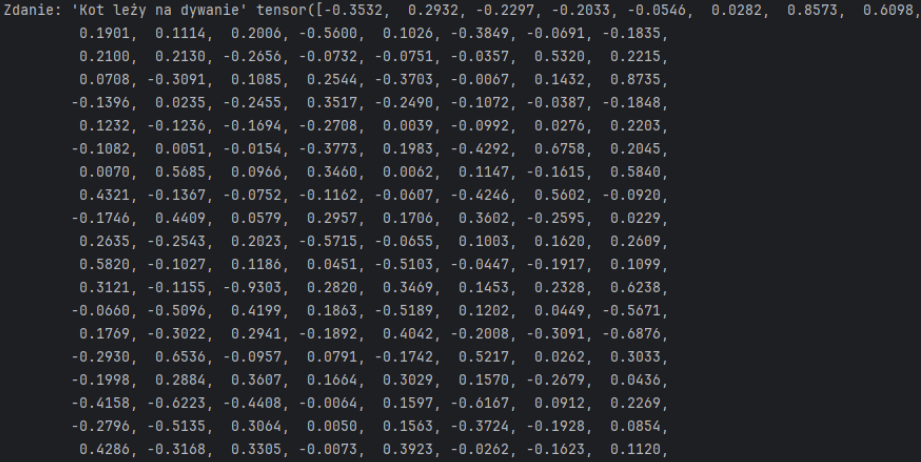
C’est pourquoi certains ont appelé les chatbots des « perroquets stochastiques ». Le LLM en action ressemble un peu à un perroquet complexe : il répète des mots qu’il ne comprend pas.
Pour un trader qui veut qu’un chatbot lui écrive une stratégie toute faite et qui, pire encore, ne peut pas programmer ou disséquer la logique de ses propres idées, cela a d’énormes implications. Si nous demandons au LLM d’écrire un système de négociation, le modèle se référera au code sur lequel il a été formé. Étant donné que la plupart des stratégies accessibles au public (qui ont servi de données d’entraînement) ont peu de chances de battre le marché (c’est-à-dire qu’il est absurde de les utiliser), vous obtiendrez un code sans valeur qui a peu de chances d’être plus performant qu’une stratégie aléatoire tirée de GitHub et écrite par un humain. Et s’il obtient des résultats suspects, c’est qu’il est probablement défectueux.



, de l’Ukraine (NSSMC), de l’Irlande (CBI), de Hong Kong (SFC), de la Nouvelle-Zélande (FMA) et du Canada (ASC, AMF) | Avril 2025 #2")










